Hi Foxel!
The normal characters of a string are between 32(space) and 127.
It is possible that some systems have an other length for different characters. See UTF8 by Wikipedia
Code:
//converts a signed char to int
int atoint(char letter)
{
int rewer;
if ( letter < 0)
rewer = letter + 256;
else rewer = (int)letter;
return rewer;
}
// returns the length of a character given by UTF 8 in Byte
short getcharart(char letter)
{
short rewer = -1;
int bu = atoint(letter);
if (bu < 192) rewer = 1;
if ((bu >= 192) && (bu < 224)) rewer = 2;
if ((bu >= 224) && (bu < 240)) rewer = 3;
if (bu >= 240)rewer = 4;
return rewer;
}
For some operations it is useful to know how much byes are need do show
a character.
Here some old charts of ASCII:

and the OLD for 128 to 255:

I think it don*t works without UTF8.
Here the old sens of the characters from 0 the 32:
Useful for old printers, RS 232:
00 NULL, no Operation,
01 Start of Heading SOH
02 Start of Text STX
03 End of Text ETX
04 End of Transmission EOT
05 Enquiry ENQ
06 Acknowledge ACK
07 Bell BEL
08 Backspace BS
09 HT Horizontal Tabulation
10 Line Feed LF
11 Vertical Tabulation VT
12 Form Feed FF
13 Carrige Return CR
14 Shift out SO
15 Shift in SI
16 Data Link Escape DLE
17 Device Control 1 DC1
18 Device Control 2 DC2
19 Device Control 3 DC3
20 Device Control 4 DC4
21 Negative Acknowledge
22 Synchronous Idle SYN
23 End of Transm.Block ETB
24 Cancel CAN
25 End of Medium EM
26 Substitute SUB Character
27 Escape ESC
28 File Separator FS
29 Group Separator GS
30 Record Separator RS
31 Unit Separator US
32 Space SP
It is possible when you take for example strlen() to get the length of
a string, you get the length in byte not in characters when you use
a mutated vowel like some german characters in a string.
So it can be that wrong results are given when letters are encrypt
without this.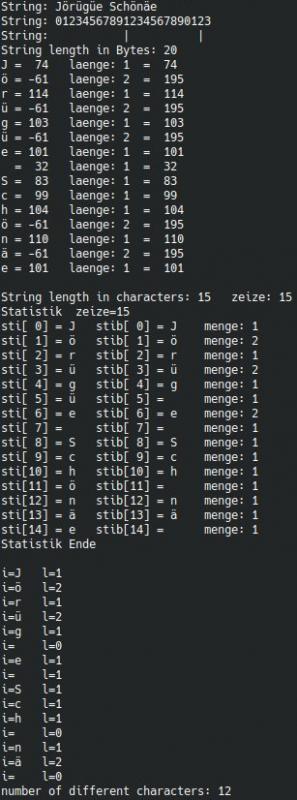
Sorry for this example i have only a source in cpp:
here at first main.cpp:
Code:
// string::at
#include "sringat.h"
int main ()
{
//char bu;
int lge = -1, i, bulen = 0, zeize = 0, anzle = 0;
short busta[20] = {0};
std::string str ("Jörügüe Schönäe");
std::string dummy = "";
std::string sti[20] = {""};
std::string stib[20] = {""};
std::cout << "String: " << str << std::endl;
std::cout << "String: 01234567891234567890123" << std::endl;
std::cout << "String: | |" << std::endl;
lge = str.length();
std::cout << "String length in Bytes: " << lge << std::endl;
bulen = letterlaenge(str, &sti, &zeize);
std::cout << std::endl;
std::cout << "String length in characters: " << bulen << " zeize: " << zeize << std::endl;
initbusta_with_1(&busta, zeize);
Zaehle_Mehrfach_Zeichen_in_sti(sti, &busta, zeize);
copy_sti_to_stib(sti, &stib, zeize);
Streiche_doppelte_Zeichen(sti, &stib, &zeize);
// Zeige Statistikfeld
ShowStatistik(sti, stib, busta, zeize);
std::cout << std::endl;
for (i= 0; i < zeize; i++)
{
lge = stib[i].length();
if (lge > 0) anzle++;
{
std::cout << "i=";
if (lge == 0) std::cout << " ";
else std::cout << stib[i];
std::cout << " l=" << lge << std::endl;
}
}
std::cout << "number of different characters: " << anzle << std::endl << std::endl;
return EXIT_SUCCESS;
}
now stringat.h
Code:
#ifndef SRINGAT_INC_
#define SRINGAT_INC 1
#include <iostream>
#include <string>
#include <iomanip>
#include <cstdlib>
int atoint(char letter);
short getcharart(char letter);
int letterlaenge(std::string str, std::string (*sti)[20], int *zeichze);
void ShowStatistik(std::string sti[20], std::string stib[20], short busta[20], int zeize);
void initbusta_with_1(short (*busta)[20], int zeize);
void copy_sti_to_stib(std::string sti[20], std::string (*stib)[20], int zeize);
void Zaehle_Mehrfach_Zeichen_in_sti(std::string sti[20], short (*busta)[20], int zeize);
void Streiche_doppelte_Zeichen(std::string sti[20], std::string (*stib)[20], int *zeize);
#endif
at last stringat.cpp
Code:
#include "sringat.h"
//converts signed char to int
int atoint(char letter)
{
int rewer;
if ( letter < 0)
rewer = letter + 256;
else rewer = (int)letter;
return rewer;
}
// returns by UTF 8 laenth of characters in Byte
short getcharart(char letter)
{
short rewer = -1;
int bu = atoint(letter);
if (bu < 192) rewer = 1;
if ((bu >= 192) && (bu < 224)) rewer = 2;
if ((bu >= 224) && (bu < 240)) rewer = 3;
if (bu >= 240)rewer = 4;
return rewer;
}
// length of string
int letterlaenge(std::string str, std::string (*sti)[20], int *zeichze)
{
std::string dummy = "";
int i, bu = 0, sl = 1, lge = -1, bulen = 0, zeize = 0;
lge = str.length();
bulen = lge;
for (i = 0; i < lge; ++i)
{
bu = str[i];
sl = getcharart(bu);
dummy = str.substr(i,sl);
if(sl > 1 ) i += (sl - 1);
bulen -= (sl - 1);
(*sti)[zeize] = dummy;
zeize++;
//std::cout << str.at(i) << " = " << int atoint(str.at(i)) << std::endl;
std::cout << dummy << " = " << std::setw(3) << bu << " laenge: " << sl << " = " << atoint(bu) << std::endl;
}
*zeichze = zeize;
return bulen;
}
void ShowStatistik(std::string sti[20], std::string stib[20], short busta[20], int zeize)
{
int i;
std::cout << "Statistic zeize=" << zeize << std::endl;
for (i = 0; i < zeize; ++i)
{
std::cout << "sti[" << std::setw(2) << std::setfill(' ') << i << "] = " << sti[i];
std::cout << " stib[" << std::setw(2) << std::setfill(' ') << i << "] = " << std::setw(1) << std::setfill(' ') << stib[i];
std::cout << " number: " << busta[i] << std::endl;
}
std::cout << "Statistic End" << std::endl;
}
void initbusta_with_1(short (*busta)[20], int zeize)
{
for (int i = 0; i < zeize; i++) (*busta)[i] = 1;
}
void copy_sti_to_stib(std::string sti[20], std::string (*stib)[20], int zeize)
{
for (int i = 0; i < zeize; i++)
(*stib)[i] = sti[i];
}
// gets characters where are more as on time in string
void Zaehle_Mehrfach_Zeichen_in_sti(std::string sti[20], short (*busta)[20], int zeize)
{
for (int i = 0; i < zeize; i++)
{
for (int j = i + 1; j < zeize; j++)
if (sti[i].compare(sti[j]) == 0) (*busta)[i]++;
}
}
// deletes charactes where ar more as one time in string
void Streiche_doppelte_Zeichen(std::string sti[20], std::string (*stib)[20], int *zeize)
{
for (int i = 0; i < *zeize; i++)
{
for (int j = i + 1; j < *zeize; j++)
if (sti[i].compare(sti[j]) == 0) (*stib)[j] = "";
}
}
Sorry, exaple is coded in german language, some details i'd tranlated in
english the last 5 minutes. But i hope it is useful for you.






